내일배움단 Web3.3
[웹개발 종합반] 3주 3일차 개발일지(3주 10-15강, 숙제)
💻TIL Web.303
1. MongoDB와 Robo 3T
MongoDB는 데이터베이스(DB), 즉 데이터를 쌓아두는 프로그램이다. MongoDB는 컴퓨터에서 돌아가고는 있지만 눈에는 보이지 않는데, 다른 말로 그래픽 인터페이스(GUI, Graphic User Interface)를 제공하지 않는다. 따라서 데이터베이스 내부를 살펴보기 위해 Robo 3T 프로그램을 사용하며, MongoDB의 데이터를 시각화해 값을 확인한다.
2. 데이터베이스(DB) 알아보기
1) DB를 사용하는 이유
데이터베이스를 사용하는 이유는 무엇일까? 데이터를 잘 쌓아두려고? 데이터를 잘 가져다 쓰려고? 정답은 ‘데이터를 잘 가져다 쓰기 위해서’이다. 책을 보관하기 위해서가 아닌, 책을 한눈에 잘 찾기 위해 책장을 정리해 사용하는 것과 같은 이치다. 따라서 데이터베이스 프로그램을 만드는 회사들은 ‘우리는 이렇게 쌓기 때문에 데이터를 더 잘 가져다 쓸 수 있어’를 어필한다.
2) SQL과 NoSQL
데이터베이스에는 두 종류가 있다. SQL, 그리고 ‘Not Only SQL’을 뜻하는 NoSQL이다. SQL(Structured Query Language)은 미리 만들어둔 칸에 데이터를 채워나가며 저장하는 방식으로, 열과 행이 정해진 엑셀과 그 방식이 비슷하다. 빈 값이 있으면 그 칸은 비운 채로 다음 칸에 값을 입력한다. 새로운 값이 추가될 때, 그 값에 해당하는 새로운 열이나 행을 만들어야 하고, 값이 추가되기 전의 데이터 값들을 모두 공란으로 채워야 하므로 값의 변경에 제약이 있다. 하지만 일관되고 정형화된 형식을 가지는 만큼, 데이터를 가져다 사용하거나 분석하는 데 효율적이다. 대표적으로 MS-SQL, My-SQL, 오라클이 있다.
NoSQL은 정해진 칸 없이, 각 데이터를 딕셔너리(Object) 형태로 저장한다. 칸이 정해진 것이 아니기 때문에, 딕셔너리가 가지는 값들이 모두 같을 필요가 없다. 따라서 새 값이 추가될 때 이전의 모든 값들에 공란을 채울 필요가 없다. 이렇듯 자유로운 형태로 데이터를 쌓을 수 있으므로 데이터 변경이 자유롭고 유연하다는 장점이 있다. 초기 스타트업이나 서비스들이 많이 이용한다. 대표적으로 MongoDB가 있다.
서버란 컴퓨터의 역할이다(‘컴퓨터에서 서버라는 프로그램을 돌리자’, ‘컴퓨터에서 DB라는 프로그램을 돌리자.’). DB 또한 하나의 프로그램이자 컴퓨터의 역할(서버)로, 이는 컴퓨터나 하드웨어 개념이 아니다. 한 컴퓨터는 여러 가지 역할을 만들 수 있다. 하나의 컴퓨터에서 DB도 돌리고 서버도 돌리고 크롤링도 할 수 있다는 뜻이다.
3. pymongo로 DB 조작하기
파이썬으로 MongoDB를 조작하기 위해, pymongo라는 라이브러리를 이용한다. PyCharm > Settings > + > pymongo를 검색하고 설치하자.
1) pymongo 시작하기
pymongo도 웹 크롤링과 마찬가지로 기본 코드가 필요하다. 아래 코드를 파일에 붙여넣은 후 코드 입력을 시작하자.
# pymongo 사용 선언
from pymongo import MongoClient
# 내 컴퓨터에서 돌아가고 있는 mongoDB에 접속
client = MongoClient('localhost', 27017)
# dbsparta라고 하는 DB 이름으로 접속
# 해당 이름이 없을 경우 새로 만들어짐
db = client.dbsparta
📒 pymongo에는 insert, find, update, delete가 있으며, 각각 데이터 입력, 탐색, 업데이트, 삭제를 담당한다.
- 사용할 코드 미리보기
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
same_ages = list(db.users.find({'age':21},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})
2) insert
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
위의 코드를 실행시키면 아래 화면과 같이 PyCharm 프로그램에서는 아무런 결과가 뜨지 않는다. 하지만 Robo 3T 프로그램에 접속하면 입력된 데이터를 엑셀 형식으로 볼 수 있다.
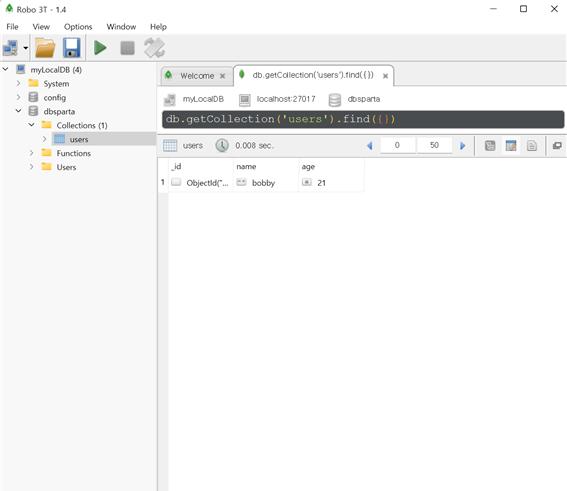
입력한 코드를 살펴보자. mongoDB는 딕셔너리(Object) 형태의 데이터를 저장하는 NoSQL이므로, 딕셔너리 형태의 doc를 만들었다. 이 doc를 db.users에 넣는다. 정해진 형식 없이 데이터를 자유롭게 넣는다 하더라도, 어느 정도 비슷한 데이터끼리 쌓아두면 편리할 것이다. users는 db의 컬렉션(collection) 개념이라 생각하면 편하다. 즉 코드 마지막 줄의 db.users.insert_one(doc)란 ‘db(dbsparta라는 이름의 DB)의 users 컬렉션에 doc 데이터를 하나 입력(insert_one)하겠다’라는 의미다. 앞으로 배워볼 find, update, delete 모두 같은 형태를 사용하게 된다.
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
doc = {'name':'john','age':27}
db.users.insert_one(doc)
앞에서 사용한 코드와 같은 형태로 데이터 값을 달리해서 실행(Ctrl+Shift+F10)시키면 Robo 3T 화면에서 값이 추가된 것을 확인할 수 있다.
3) find
① 조건이 있는 find
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
same_ages = list(db.users.find({'age':21},{'_id':False}))
print(same_ages)
# [{'name': 'bobby', 'age': 21}, {'name': 'jane', 'age': 21}]
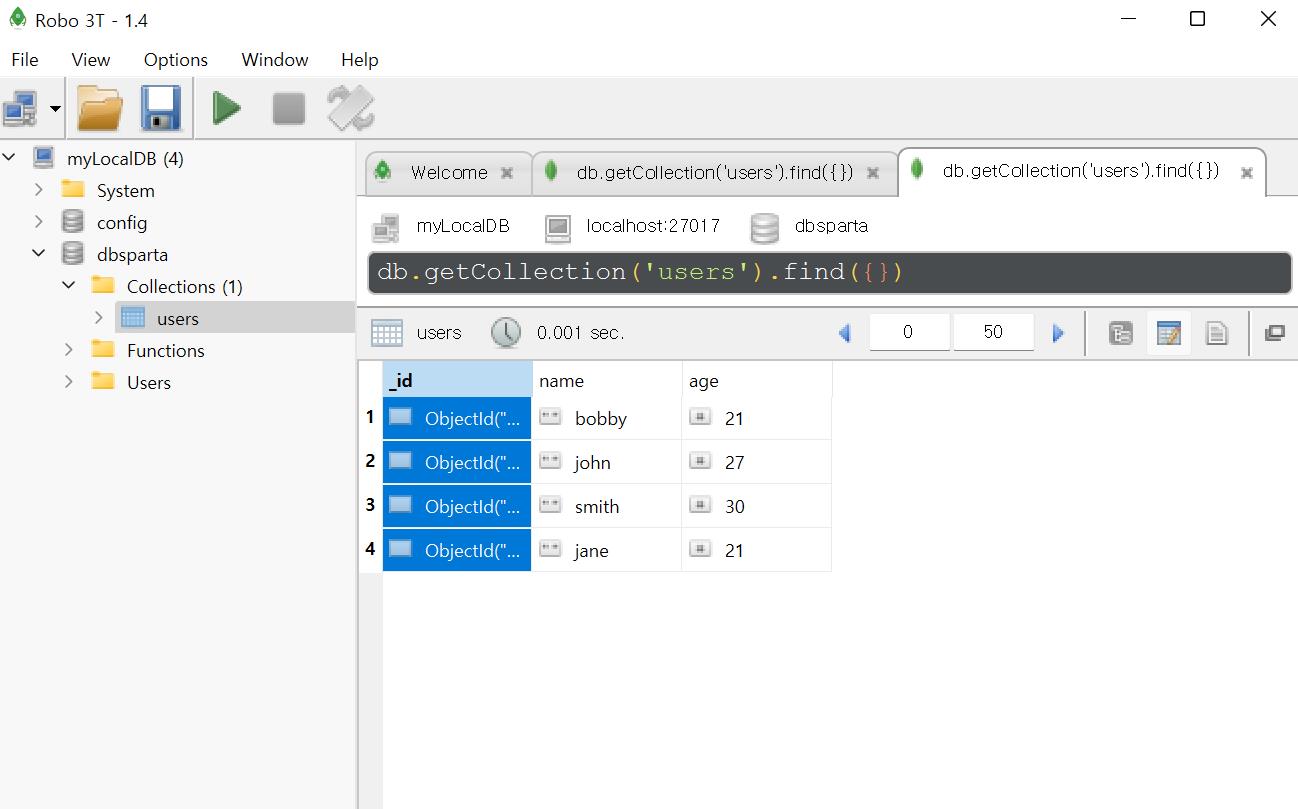
코드부터 살펴보면, 어떠한 값을 찾아서 same_ages라는 변수에 넣은 것을 확인할 수 있다. 이 same_ages를 출력해보면, 리스트(array) 안에 조건({'age':21})을 만족하는 두 딕셔너리(object)가 들어와 있다. 아래 find_one과 달리, 탐색한 값들을 리스트(array)에 넣어야 하기 때문에 list()를 사용해야 한다. list() 없이 find를 사용할 경우 에러가 뜬다.
{'_id': False}란 Robo 3T에서의 ‘_id’ 속성(아래 사진 참고)은 나타내지 않는다는 의미다. ‘_id’ 값은 랜덤으로 부여되는 고유한 값이며, 보통 데이터를 탐색할 때 id는 보이지 않게 처리하는 경우가 많다. [관련 문서1를 찾아보니, 속성값으로 0(출력 X)과 1(출력 O)을 부여하는 방식으로 해당 속성의 출력 여부를 결정할 수도 있다. 또한 same_ages는 리스트(array) 안에 딕셔너리(object)가 있는 구조이므로, 반복문을 활용해 각 요소를 한 줄씩 출력할 수도 있다.
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
same_ages = list(db.users.find({'age':21},{'_id':False}))
for person in same_ages:
print(person)
# {'name': 'bobby', 'age': 21} {'name': 'jane', 'age': 21}
# 1의 값이 부여된 속성들만 반환함
# _id 속성은 0이나 False 값을 주지 않으면 자동 반환됨
same_ages = list(db.users.find({'age':21}, {'_id': 0, 'name': 1}))
print(same_ages)
# [{'name': 'bobby'}, {'name': 'jane'}]
② 조건이 없는 find
위처럼 조건을 부여해 이를 만족하는 데이터를 탐색할 수도 있지만, 조건 없이 모든 document를 가지고 올 수도 있다. 그럴 때는 조건이 들어가는 위치에 빈 중괄호({})를 써주면 된다.
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
same_ages = list(db.users.find({},{'_id':False}))
print(same_ages)
# [{'name': 'bobby', 'age': 21}, {'name': 'john', 'age': 27}, {'name': 'smith', 'age': 30}, {'name': 'jane', 'age': 21}]
③ find_one
여러 개의 데이터 값을 담은 리스트(array)가 아닌, 조건을 만족하는 하나의 값만을 가지고 오고 싶을 때는 find_one을 이용한다. 만족하는 값이 여러 개 있을 때는 제일 위에 있는 값을 가지고 온다.
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
user = db.users.find_one({'name':'bobby'}, {'_id': False})
print(user)
# {'name': 'bobby', 'age': 21}
4) update
① update_one
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
코드 마지막 줄은 ‘name’이 ‘bobby’인 데이터 하나를 찾아서, ‘age’를 19로 변경하라는 뜻이다. 데이터를 업데이트할 때는 colleciton 이름(users)이 데이터가 들어 있는 곳과 일치하는지 체크해야 한다. 변경된 데이터 값은 Robo 3T에서 확인할 수 있다.
② update_many
update_many는 update_one과 달리, 조건을 만족하는 모든 데이터의 속성값을 변경한다. 한 번에 모든 데이터를 다 바꾼다는 것은 위험하기 때문에 잘 사용하지는 않는다.
5) delete
delete도 많이 이용하는 속성은 아니다. delete_one과 delete_many가 있다.
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
db.users.delete_one({'name':'bobby'})
4. 웹 스크래핑 결과 저장하기(insert)
hello.py 파일에서 웹 스크래핑 결과를 가져와보자. 코드 마지막에서 불러온 데이터를 print하는 대신 DB에 입력하면 된다. DB를 사용하기 위해 기본 코드 세 줄을 코드 최상단에 가져온다.
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303', headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
a_tag = tr.select_one('td.title > div > a')
if a_tag is not None:
rank = tr.select_one('td > img')['alt']
title = a_tag.text
star = tr.select_one('td.point').text
doc = { 'rank': rank,
'title': title,
'star': star
}
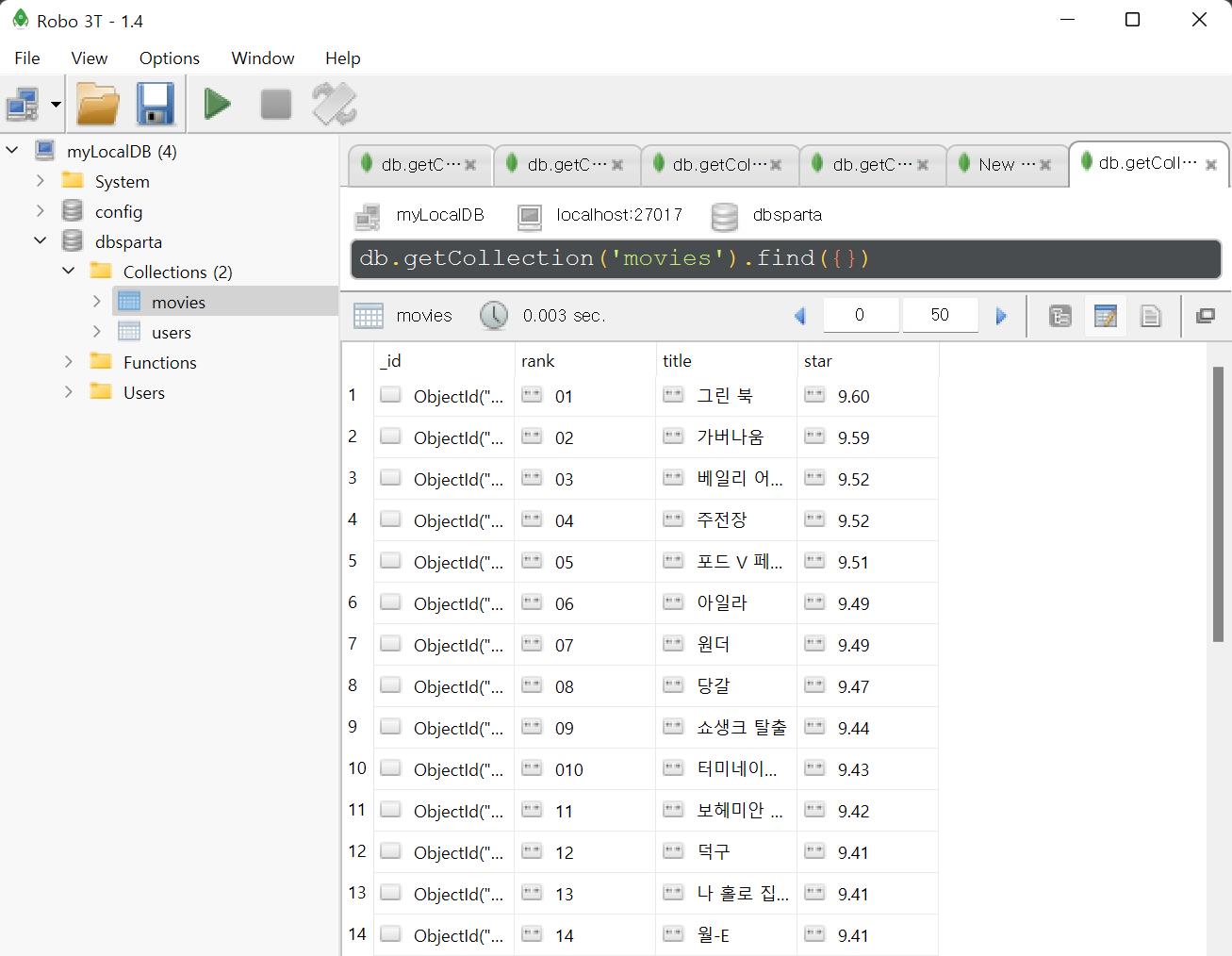
db.movies.insert_one(doc)
위처럼 doc라는 새로운 딕셔너리를 만들고, 속성과 속성값을 입력한다. 앞에서 사용한 users collection 대신 movies collection에 데이터를 insert하면 새로운 collection이 생성되며 그곳에 데이터가 입력된다. Robo 3T 프로그램에서 새로 생성된 collection과 입력된 데이터를 확인할 수 있다.
5. 웹 스크래핑 결과 이용하기(find, update)
1) 영화제목 ‘매트릭스’의 평점 가져오기
matrix = db.movies.find_one({'title':'매트릭스'}, {'_id': False})
print(matrix['star'])
# 9.39
하나의 값만을 찾으므로 find_one을 이용하며, 출력창에는 딕셔너리 형태가 아닌 평점 값만 찍혀야 하므로, ['']로 star 속성의 값만을 출력한다.
2) ‘매트릭스’와 같은 평점의 영화 제목들 가져오기
matrix = db.movies.find_one({'title':'매트릭스'}, {'_id': False})
star = matrix['star']
matrixList = db.movies.find({'star': star}, {'_id': False})
for movie in matrixList:
print(movie['title'])
# 해설 코드
target_movie = db.movies.find_one({'title':'매트릭스'})
target_star = target_movie['star']
movies = list(db.movies.find({'star':target_star}))
for movie in movies:
print(movie['title'])
처음에는 list()를 사용해 평점이 같은 영화들을 하나의 리스트(array)에 담으려고 했지만, 리스트 내에서 title 속성값만을 출력하려고 하니 에러가 떴다. 그래서 for...in 반복문을 사용해 find로 찾아낸 여러 값들을 하나하나 출력하는 방식을 사용했다. star라는 변수를 사용하려면 {}나 ${}를 사용할 필요 없이 그냥 변수명만 입력하면 된다.
해설 코드를 보니, 어차피 title 속성값만 출력할 것이기 때문에 find를 사용할 때 {'_id': False}를 써줄 필요가 없었다. 또, 반복문은 리스트와 함께 이용되므로 list()를 사용해 찾아낸 값들을 리스트에 담아준다.
3) ‘매트릭스’ 영화 평점 0으로 만들기
db.movies.update_one({'title':'매트릭스'}, {'$set': {'star': 0}})
조건에 만족하는 하나의 값만을 업데이트하는 것이므로 update_one을 사용해야 한다. update는 없음!
4) 데이터 자료형 통일하기

위 사진을 보면 영화 ‘매트릭스’와 다른 영화들의 평점 표시가 다른 것을 확인할 수 있다. 다른 영화들의 평점은 “9.41”처럼 문자열 형태("")로 되어 있다. 반면 ‘매트릭스’의 평점은 숫자(#)다. 데이터를 탐색해 사용할 때 자료형이 다르면 결과가 정확하지 않을 수 있다. 자료형을 통일하는 것이 추후 관리에 편하기 때문에, 위의 업데이트 시 0이 아닌 '0'을 넣어준다.
db.movies.update_one({'title':'매트릭스'}, {'$set': {'star': '0'}})
3주차 숙제: 지니뮤직 스크래핑
지니뮤직 사이트의 1~50위 순위, 곡 제목, 가수를 스크래핑해보자.
💡힌트: 파이썬 문자열 자르기/파이썬 공백 제거를 구글링해서 문자열을 깔끔하게 출력해보자!
1) 데이터 태그 분석하기
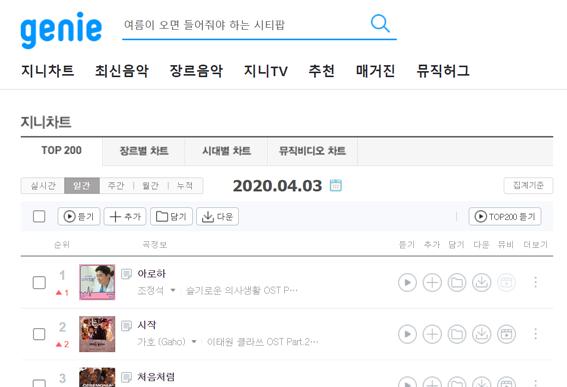
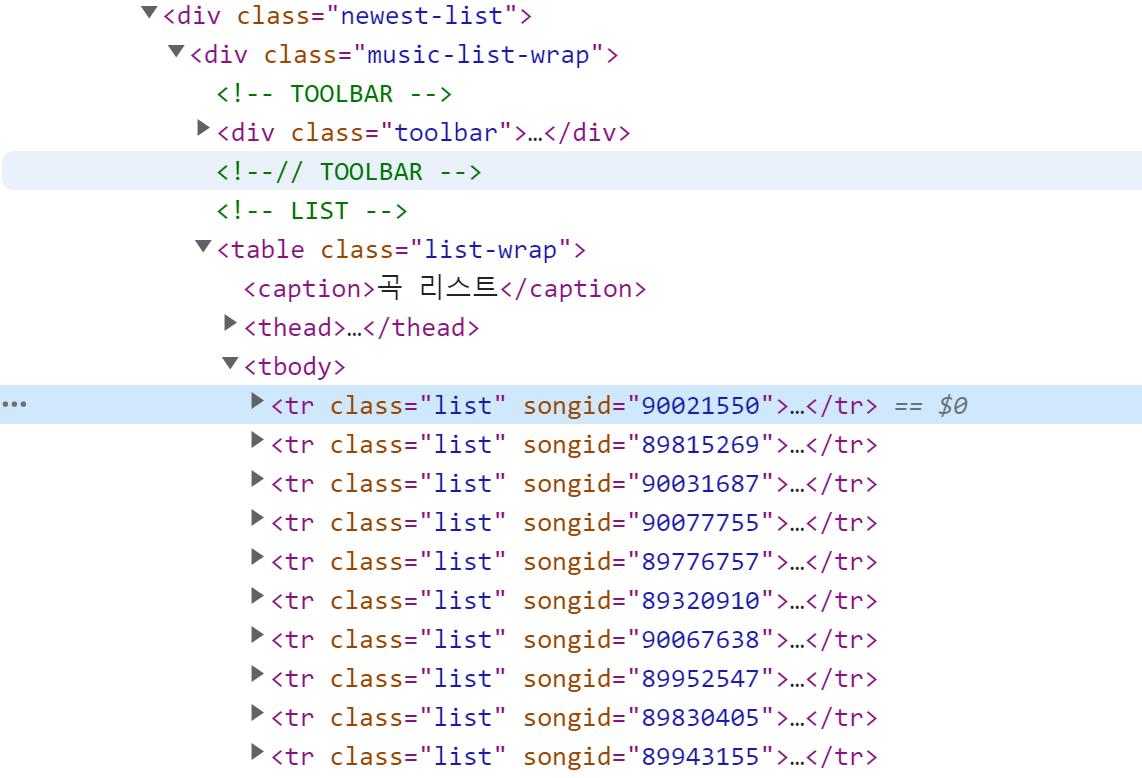
# 화면상 한 줄
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1)
# 순위
<td class="number">1
<span class="rank">
<span class="rank"><span class="rank-up">1<span class="hide">상승</span></span></span>
</span>
</td>
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.number
# 제목
<a href="#" class="title ellipsis" title="재생" onclick="fnPlaySong('90021550','1');return false;">아로하</a>
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.title.ellipsis
# 가수
<a href="#" class="artist ellipsis" onclick="fnViewArtist('61153290');return false;">조정석</a>
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.artist.ellipsis
태그를 보니 tr 태그까지가 한 줄이며, 순위와 제목, 가수는 각각 태그의 텍스트를 추출하면 될 것 같다.
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
print(trs)
한 줄씩의 태그들을 다 출력해봤을 때 None 값이 보이지 않기 때문에, 조건문은 쓰지 않아도 될 것 같다.
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
rank = tr.select_one('td.number').text
title = tr.select_one('td.info > a.title.ellipsis').text
artist = tr.select_one('td.info > a.artist.ellipsis').text
print(rank, title, artist)
1
1상승
아로하 조정석
코드를 실행했더니 순위 태그의 ‘1’, ‘상승’과 같은 자식 태그들의 텍스트도 함께 출력되었고, 출력되는 값 사이에 공백이 너무 많았다.
2) 문자열 자르기, strip()
글자 사이의 공백을 없애는 방법을 구글링한 결과, strip()을 사용해야 한다는 것을 알았다.
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
rank = tr.select_one('td.number').text.strip()
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
artist = tr.select_one('td.info > a.artist.ellipsis').text.strip()
print(rank, title, artist)
1
1상승 아로하 조정석
2
2상승 시작 가호 (Gaho)
코드를 실행했더니 제목과 가수 사이의 공백은 없어졌지만, 여전히 자식 태그(span 태그)의 텍스트도 함께 출력된다.
3) 자식 태그 없애기, clear()
자식 태그를 없앨 수 있는 방법을 구글링해보니, clear(), decompose(), replace()의 세 가지 방안이 있었다. 이 중 clear()를 사용해 td 태그의 자식 태그인 span 태그를 없앤 후 값을 출력했다.
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
# 순위에 해당하는 모든 태그
rank = tr.select_one('td.number')
# td 태그 내 span 태그 찾아서 제거
rank.find('span').clear()
# span이 제거된 후 td 태그의 텍스트만을 반환
rankOnly = rank.text.strip()
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
artist = tr.select_one('td.info > a.artist.ellipsis').text.strip()
print(rankOnly, title, artist)
1 아로하 조정석
2 시작 가호 (Gaho)
3 처음처럼 엠씨더맥스 (M.C the MAX)
4 이제 나만 믿어요 임영웅
5 아무노래 지코 (ZICO)
6 흔들리는 꽃들 속에서 네 샴푸향이 느껴진거야 장범준
4) 나의 코드
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&ymd=20200403&hh=23&rtm=N&pg=1', headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
rank = tr.select_one('td.number')
rank.find('span').clear()
rankOnly = rank.text.strip()
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
artist = tr.select_one('td.info > a.artist.ellipsis').text.strip()
print(rankOnly, title, artist)
5) 해설 코드, .text[start:end]
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&ymd=20200403&hh=23&rtm=N&pg=1',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
rank = tr.select_one('td.number').text[0:2].strip()
artist = tr.select_one('td.info > a.artist.ellipsis').text
print(rank, title, artist)
해설 코드를 보니, 자식 태그를 아예 지우는 방향이 아니라 text[0:2]를 이용해 index를 기준으로 텍스트를 잘라낸 것 같다. 내 코드는 아예 자식 태그를 없애는 방법이라, 만약 span 태그도 출력했어야 한다면 잘못된 코드일 것이다. 이렇게 필요한 부분만 잘라서 출력하는 것이 더 나은 코드다.
공백을 제거하는 strip() 이외에, index 0부터 2까지의 문자만 .text[0:2] 형식으로 출력할 수 있다. text[0:1]로 바꿔보니 숫자 하나만 출력되는 걸로 보아 끝 지점은 포함되지 않는 것 같다. 검색해보니 [1:-1](앞에서 두 번째 글자부터 뒤에서 두 번째 글자까지를 나타낸다)처럼 음수도 사용 가능하다. 시작점과 끝점의 index를 입력받고, 끝점 index는 포함되지 않는다는 점에서 자바스크립트의 substring() method와 비슷하다.
Leave a comment